Reiner Textscore vs. smarte Listings: Was GA4-Signale im Ranking ändern
BM25 und TF-IDF ranken Shop-Treffer rein nach Textscore und ignorieren die Conversion-Realität. Wer GA4-Klick-, Add-to-Cart- und Kaufsignale ins Ranking holt, kombiniert mit semantischer LLM-Intent-Schicht und Recency-Gewichtung, holt zweistellige Conversion-Lifts. Dieser Artikel erklärt die Score-Komposition, das Cold-Start-Problem und das saubere A/B-Test-Setup mit NDCG, MRR und Search Revenue per Session.
Wenn der Bestseller auf Platz 14 liegt
Ein Sportartikel-Shop verkauft Laufschuhe. Die meistgekaufte Variante des Jahres ist ein neutraler Straßenschuh in Größe 42, der laut Analytics-Daten in der Suche nach "Laufschuh Herren" eine Conversion-Rate von 11 Prozent erzielt. Das Produkt rankt in der Shop-Suche auf Position 14 in der zweiten Reihe der Ergebnisliste, weil sein Titel das Keyword nur einmal enthält. Auf den Plätzen eins bis fünf stehen Schuhe mit "Laufschuh Herren" mehrfach in Titel, Untertitel und Tags, deren tatsächliche Conversion-Rate aber unter 2 Prozent liegt. Der Kunde scrollt nicht bis Position 14, klickt auf Platz drei, bricht ab, schließt das Tab.
Genau dieser Effekt wiederholt sich in praktisch jedem mittelgroßen Shop, der mit einer klassischen Text-Match-Suche arbeitet. Die Suche tut technisch, was sie soll. Sie matched den Suchbegriff gegen das Produktfeed und sortiert nach einem Score, der ausschließlich aus dem Text berechnet wird. Was sie nicht weiß, ist welche Produkte tatsächlich gekauft werden, welche eine hohe Klickrate haben und welche im Warenkorb landen.
Diese Lücke ist kein Detail. Sie ist die strukturelle Schwäche jeder Suche, die nur Textscore kennt und keine Verhaltenssignale. Wer shop suche ranking optimieren ernsthaft angeht, muss diese Lücke schließen. Der Hebel dafür liegt in den GA4-Daten, die jeder Shop ohnehin produziert. Dieser Artikel zeigt, was reiner Textscore wirklich misst, warum BM25 und TF-IDF allein im E-Commerce zu kurz greifen, wie GA4-Signale das Ranking smarter machen, wie der Cold-Start für neue Produkte gelöst wird und wie eine Hybrid LLM Search alle drei Schichten kombiniert.
Was reiner Textscore wirklich misst (und was nicht)
Praktisch jede klassische Shop-Suche, die auf Elasticsearch, OpenSearch oder Solr basiert, rankt Treffer per default mit einem von zwei Verfahren: BM25 oder TF-IDF. Beide gehören zur Familie der Bag-of-Words-Modelle und berechnen einen Relevanz-Score allein aus der Verteilung der Suchwörter im Produkttext.
TF-IDF steht für Term Frequency mal Inverse Document Frequency. Die Term Frequency zählt, wie oft ein Suchbegriff im Produkttext vorkommt. Die Inverse Document Frequency gewichtet seltene Begriffe höher als häufige. Ein Produkttitel mit dem Wort "Titan" bekommt einen höheren Score als ein Titel mit dem Wort "Schwarz", weil "Titan" seltener im Gesamtkatalog vorkommt und damit als informativer gewertet wird.
BM25 ist die seit 1994 etablierte Erweiterung, die zusätzlich die Dokumentlänge normalisiert und die Term-Frequenz logarithmisch sättigt. Damit profitieren kurze Titel und kurze Produktbeschreibungen nicht mehr automatisch von einer höheren Wort-Dichte. BM25 ist heute der Standard-Algorithmus in praktisch jedem Such-Backend, das nicht explizit etwas anderes konfiguriert hat.
Was beide Verfahren technisch gut können: Suchbegriffe gegen Produkttexte matchen, Treffer ohne den Suchbegriff aussortieren und die übrigen Treffer in eine konsistente Reihenfolge bringen. Was beide nicht können: irgendetwas über das tatsächliche Verhalten der Käufer wissen.
Drei strukturelle Schwächen folgen daraus.
Erstens: Keyword-Stuffing-Anfälligkeit. Wer im Produkttitel "Laufschuh Herren Sneaker Sport Running Trail" schreibt, ranked unter BM25 höher als ein nüchterner Titel "Pegasus 41 Neutralschuh". Selbst wenn das letztere Produkt zehnmal so oft gekauft wird. BM25 ist eine reine Textanalyse, sie hat keinen Zugriff auf die Conversion-Realität.
Zweitens: Synonyme und Compound-Splits. "Sommerkleid" und "Kleid Sommer" sind für BM25 zwei verschiedene Begriffe, weil die Tokenisierung die Wörter unterschiedlich zerlegt. Wer wissen will, wie diese Vorstufe technisch funktioniert, findet die Mechanik in unserem Beitrag zu Tokenseparatoren in der Shop-Suche. Und wer die Schreibfehler-Schicht verstehen will, lese parallel den Artikel zu Fehlertoleranz auf Feldebene. Beide sind die Voraussetzung dafür, dass das Ranking überhaupt einen sinnvollen Kandidaten-Pool bekommt.
Drittens und entscheidend: Keine Conversion-Signale. Ob ein Produkt seit drei Jahren auf Lager liegt und nie geklickt wird oder ob es der Bestseller der Saison ist, bleibt für BM25 unsichtbar. Beide Produkte werden gleich behandelt, solange ihr Text-Score gleich ist. Genau hier setzt der wichtigste Ranking-Hebel an, den klassische Shop-Suchen nicht haben.
Die fehlende Signal-Schicht: Was GA4 weiß, was die Suche nicht weiß
Google Analytics 4 trackt seit dem GA4-Standard 2023 eine Reihe von E-Commerce-Events, die für das Such-Ranking direkt relevant sind. Sieben davon sind besonders wertvoll.
view_item zählt, wie oft eine Produkt-Detail-Page aufgerufen wurde. Aggregiert über alle Suchanfragen, die zu diesem Klick geführt haben, ergibt das die klickgewichtete Sichtbarkeit pro Suchterm.
select_item trackt Klicks aus Listenansichten heraus, also auch Klicks aus der Suchergebnisseite. Das ist das primäre Signal für eine Suchterm-spezifische Click-Through-Rate, die im Ranking gewichtet werden kann.
add_to_cart zeigt, welche Produkte aus der Suche heraus in den Warenkorb gelegt werden. Dieses Signal ist deutlich stärker als ein reiner Klick, weil es eine konkrete Kaufabsicht ausdrückt.
begin_checkout und purchase sind die endgültigen Conversion-Signale. Die Conversion-Rate eines Produkts pro Suchterm ist die härteste Größe, die ein Ranking-System bekommen kann.
view_search_results und search liefern den Kontext: welche Suchanfragen wurden gestellt, wie viele Treffer wurden ausgespielt, und wie sah die Klickverteilung über die Treffer aus.
Wer diese sieben Events sauber im GA4 hat, hat damit ein vollständiges Bild jeder Suchsitzung: Suchbegriff, Trefferliste, Klick auf Treffer, Add-to-Cart, Kauf. Das ist die Datengrundlage, die ein Ranking-System braucht, um über den reinen Textscore hinauszugehen.
Die nüchterne Diagnose: in den meisten DACH-Shops liegen diese Daten in GA4 vor, fließen aber nicht zurück in die Suche. GA4 wird für Reporting und Marketing genutzt, die Such-Engine läuft autark mit BM25. Beide Systeme sehen sich nie. Die Lücke ist nicht technisch unauflösbar, sie wird in der Regel einfach nicht geschlossen, weil das Such-Backend keine Schnittstelle für Behavior-Signale hat und niemand im Team die Pipeline aufbaut.
Genau diese Pipeline ist der Hebel, den wir in unseren Audits bei Mid-Enterprise-Shops am häufigsten als Quick-Win sehen. Die GA4-Daten sind da. Sie müssen nur in das Ranking eingebunden werden.
Vom Textscore zum Hybrid-Score: Wie Listings smart werden
Ein modernes Shop-Ranking kombiniert mindestens drei Signal-Schichten zu einem einzigen Hybrid-Score. Die Reihenfolge dieser Schichten ist nicht egal.
Die erste Schicht ist textbasiert und liefert die Kandidaten-Liste. BM25 oder ein vergleichbarer Lexical-Score sortiert grob nach Wort-Match-Qualität und filtert offensichtlich irrelevante Produkte aus. Wer hier statt BM25 etwas Besseres will, kann zu einer Vektorsuche greifen, die Embeddings über Produkttext und Suchbegriff berechnet. Eine Einführung in die Mechanik finden Sie in unserem Beitrag Was ist semantische Suche. Die Vektorsuche löst das Synonym-Problem ohne manuelle Pflege und bringt semantische Nähe (etwa "Pullover" und "Sweater") in den Score ein.
Die zweite Schicht ist behavioral. Hier fließen die GA4-Signale ein: Klickrate pro Suchterm, Add-to-Cart-Rate pro Suchterm, Conversion-Rate pro Suchterm, Bounce-Rate auf der Ergebnisseite. Diese Signale werden in einen behavioralen Score umgerechnet, der das Textscore-Ergebnis multiplikativ oder additiv ergänzt. Ein Produkt mit hoher historischer Klickrate auf "Laufschuh Herren" bekommt einen Boost, ein Produkt ohne nennenswerte Interaktion bekommt keinen.
Die dritte Schicht ist semantisch und nutzt LLM-basierte Intent-Erkennung. Sie beantwortet die Frage: was meint der Kunde wahrscheinlich, wenn er "Pegasus 41" tippt? Geht es um den Schuh oder um die Schuhgröße? Will der Kunde Herren- oder Damenschuhe? Diese Schicht justiert das Ranking auf den Such-Intent und vermeidet, dass ein hochrankendes, aber falsches Produkt nach oben gespült wird.
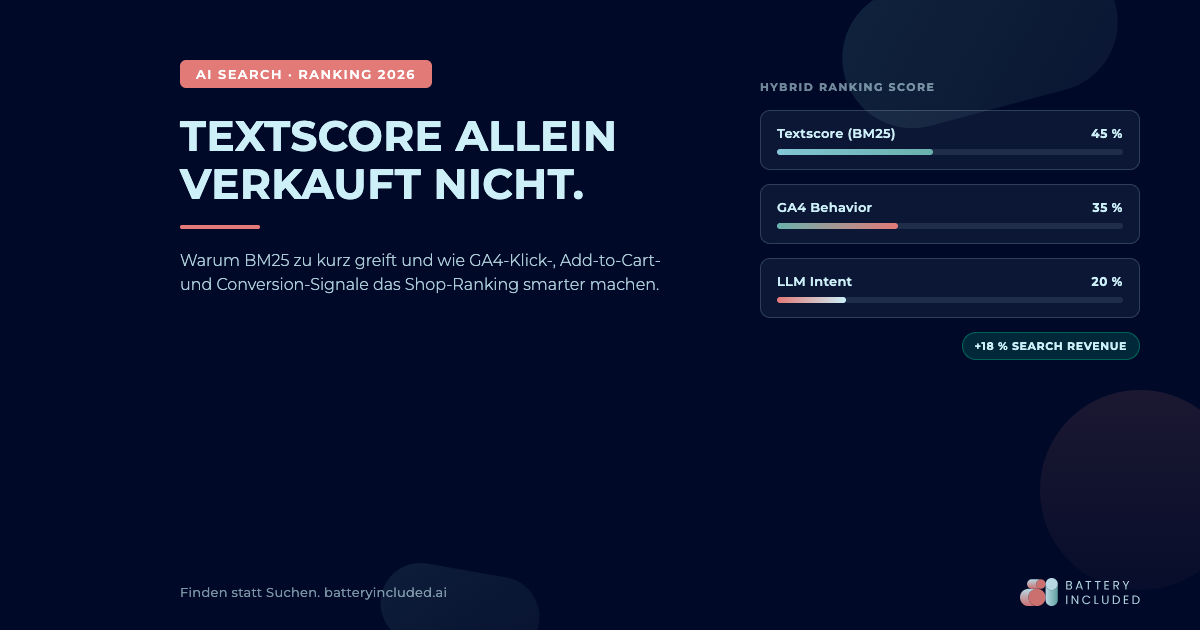
Die Gewichtung der drei Schichten ist nicht universell, sie muss pro Shop ausgesteuert werden. Eine Mischung, die in unseren Audits oft gut funktioniert, sieht so aus:
| Signal-Schicht | Gewicht | Was sie liefert |
|---|---|---|
| **Textscore (BM25 oder Vektorsuche)** | 40 bis 50 Prozent | Grobsortierung, Filterung irrelevanter Treffer |
| **GA4-Behavior-Score** | 30 bis 40 Prozent | Conversion-Realität, Bestseller-Erkennung |
| **LLM-Intent-Score** | 10 bis 20 Prozent | Semantische Nähe, Intent-Justierung |
| **Inventar-Filter** | hart (boolean) | Out-of-Stock raus, Saison-Sortiment rein |
Die Gewichte sind das Ergebnis kontinuierlicher A/B-Tests, nicht einer einmaligen Festlegung. Saisonale Shops gewichten die Behavior-Schicht stärker, Premium-Shops mit langen Erklärungs-Texten profitieren von einer höheren semantischen Schicht.
Eine Shop-Suche mit diesem dreischichtigen Ranking nennt sich in der Fachsprache Hybrid Search oder Hybrid Ranking. Wenn die dritte Schicht zusätzlich LLM-basiert ist, sprechen wir von Hybrid LLM Search. Der Unterschied zur klassischen BM25-Suche ist nicht graduell. Er ist strukturell.
Ein CTO formuliert die Praxiserfahrung mit einer Hybrid-Ranking-Suche so:
"BatteryIncluded.ai ist genau das, was man sich von moderner E-Commerce-Technologie wünscht: blitzschnelle Suche auch bei über 50.000 Produkten, volle Anpassbarkeit für komplexe Anforderungen, und ein Support, der nicht nur reagiert, sondern wirklich versteht. Stabil, skalierbar, zukunftssicher."
Österreichischer Bundesverlag Schulbuch GmbH & Co. KG
Die volle Anpassbarkeit ist genau der Punkt, der eine gewichtete Hybrid-Score-Komposition erst möglich macht. Eine fixe Score-Formel hilft nicht, wenn der Shop saisonal stark schwankt, Marken-Launches verkraften muss oder regelmäßig sein Sortiment austauscht.
Recency und Seasonality im Ranking
Behavior-Signale haben eine eingebaute Schwäche: sie sind historisch. Ein Bestseller, der seit drei Jahren gut performt, wird auch dann noch oben angezeigt, wenn das Produkt ausläuft und Nachfolger im Sortiment sind. Eine reine GA4-Gewichtung verewigt damit den Status quo.
Die Antwort lautet Recency-Gewichtung. Behavior-Signale werden zeitlich gewichtet, sodass jüngere Interaktionen stärker zählen als ältere. Eine typische Funktion ist ein exponentieller Decay über 30 oder 60 Tage: Klicks aus den letzten sieben Tagen zählen mit Faktor eins, Klicks aus dem letzten Monat mit Faktor 0,5, Klicks aus dem letzten Jahr mit Faktor 0,1. Damit kommen neue Bestseller schneller nach oben und alte Produkte rutschen ohne menschliches Zutun nach unten.
Saisonale Effekte sind die zweite zeitliche Dimension. Ein Wintermantel-Bestseller hat im Juli wenig Relevanz, auch wenn er im Januar dominiert hat. Eine Saisonkurven-Gewichtung rechnet historische Behavior-Daten relativ zur aktuellen Saison. Ein Produkt, das im aktuellen Monat des Vorjahres hoch gerankt war, bekommt einen Boost, ein Produkt, das nur in einer anderen Saison stark war, nicht.
In den DACH-Märkten ist die Saisonalität in fast jedem Sortiment relevant: Mode mit Frühjahr-, Sommer-, Herbst- und Winterkollektion, Garten mit Saisonstart im März, Sport mit Outdoor-Saison im Mai, Schulbedarf mit Spitze im August, Weihnachten in jedem Sortiment. Wer Recency und Seasonality nicht im Ranking hat, ranked im Juli Wintermäntel, weil sie im Vorjahr Bestseller waren.
Recency-Gewichtung ist mit klassischen Such-Backends technisch implementierbar, verlangt aber eine zusätzliche Pipeline, die GA4-Daten regelmäßig in den Such-Index zurückspielt. In den meisten Setups, die wir auditieren, fehlt diese Pipeline. Die Behavior-Daten werden nicht in Echtzeit, nicht täglich, nicht einmal wöchentlich aktualisiert. Das Ranking ist eingefroren auf den Stand des letzten manuellen Re-Indexing.
Cold-Start: Wenn ein Produkt noch keine Daten hat
Behavior-Signale haben eine zweite strukturelle Schwäche: für neue Produkte gibt es noch keine. Ein frisch gelisteter Artikel hat keine Klick-Historie, keine Add-to-Cart-Rate, keine Conversion-Daten. Wenn das Ranking stark auf Behavior gewichtet ist, sinkt das neue Produkt automatisch ans untere Ende der Ergebnisliste. Es bekommt nie Sichtbarkeit, generiert keine Daten und bleibt unsichtbar.
Dieses Phänomen heißt Cold-Start-Problem. Es ist nicht spezifisch für die Shop-Suche, sondern tritt überall auf, wo Verhaltenssignale ein Ranking treiben. Das Cold-Start-Problem ist einer der Gründe, warum reine Behavior-basierte Ranking-Modelle in der Praxis scheitern. Sie zementieren bestehende Bestseller und blenden Neuheiten aus.
Drei Strategien lösen das Cold-Start-Problem in einer Hybrid-Ranking-Architektur.
Erstens: Embedding-basierte Ähnlichkeit zu bestehenden Produkten. Ein neues Produkt bekommt einen vorläufigen Behavior-Score zugewiesen, der aus den Embeddings ähnlicher Produkte berechnet wird. Wenn ein neuer Laufschuh dem Bestseller "Pegasus 41" semantisch ähnlich ist, erbt er einen Teil von dessen Behavior-Score. Diese Vererbung läuft automatisch über die Vektorsuche und braucht keinen manuellen Pflegeaufwand.
Zweitens: Boost-Phase für neue Produkte. In den ersten 14 oder 30 Tagen nach Listing bekommt ein neues Produkt einen festen Sichtbarkeits-Bonus, sodass es auf den relevanten Suchergebnisseiten in den ersten Plätzen erscheint. Damit sammelt es Klick-Daten und kann nach der Boost-Phase organisch in das Behavior-getriebene Ranking übergehen.
Drittens: Sortimentsgruppen-Daten. Auch wenn ein konkretes Produkt keine Historie hat, hat seine Kategorie eine. Die durchschnittliche Conversion-Rate der Kategorie "Laufschuh Herren Neutral" liegt zum Beispiel bei 6 Prozent. Ein neues Produkt dieser Kategorie wird mit dem Gruppen-Durchschnitt initialisiert, bis eigene Daten genug Volumen haben.
Diese drei Strategien kombiniert lösen das Cold-Start-Problem strukturell. Ohne sie ist jedes behavior-getriebene Ranking ein Hindernis für Sortiments-Neuheiten und damit ein direkter Umsatz-Bremser bei Saisonwechseln und Marken-Launches.
Hybrid LLM Search als Ranking-Layer
Volt Search® von BatteryIncluded ist als entkoppelte Infrastruktur so gebaut, dass die drei Signal-Schichten ohne Custom-Pipeline kombiniert werden. Die Architektur folgt drei Prinzipien.
Erstens: die Schichten sind getrennt, aber lose gekoppelt. Token-Matching, Vektorsuche und LLM-Intent-Erkennung laufen jeweils als eigene Service-Layer. Sie können einzeln optimiert, einzeln aktualisiert und einzeln A/B-getestet werden. Ein neues Embedding-Modell ersetzt die zweite Schicht, ohne dass die erste oder dritte Schicht angepasst werden muss.
Zweitens: die Behavior-Daten werden über eine standardisierte Schnittstelle zurückgespielt. GA4-Events fließen aggregiert in einen Behavior-Index, der das Ranking pro Suchterm beeinflusst. Die Aggregation ist datenschutzkonform, weil sie auf Suchterm-Ebene aggregiert, nicht auf User-Ebene. Es gibt keine User-IDs in der Behavior-Pipeline. Cookieless, DSGVO-konforme KI, kein User-Tracking.
Drittens: die Score-Gewichtung ist konfigurierbar. Pro Shop, pro Saison, pro Marken-Launch können die Gewichte der Schichten justiert werden. Wer in der Vorweihnachtssaison stärker auf Behavior gewichten will, kann das tun. Wer für eine Neuheiten-Launch-Phase Cold-Start-Boost stärker aktivieren will, kann das auch tun. Die Konfiguration ist Code-frei, sie läuft über das Admin-Interface.
Diese Architektur ist mit klassischen Open-Source-Indizes wie Elasticsearch, OpenSearch oder Solr nicht ohne erheblichen Engineering-Aufwand erreichbar. Eine vergleichbare Pipeline selbst zu bauen, kostet typisch 50 bis 100 Personentage Initial-Aufwand und einen dauerhaften Search-Engineer im Team. Eine tiefere Betrachtung der Build-vs-Buy-Entscheidung finden Sie im Beitrag zu SaaS-Suche vs. Open Source und im breiteren Anbietervergleich unter E-Commerce Suchmaschine im Vergleich.
Ein Kunde formuliert die Praxiserfahrung mit einer Hybrid-Ranking-Architektur so:
"Ein hervorragender Dienstleister mit einem wirklich starken Tool. Der Kundensupport reagiert außergewöhnlich schnell, meist noch am selben Tag oder spätestens am nächsten Morgen. Besonders überzeugt hat uns die leistungsstarke Suchfunktion, mit der sich Synonyme, Kampagnen und viele weitere Optionen flexibel einstellen lassen."
Solit Group AG
Die flexible Einstellbarkeit von Kampagnen ist im Ranking-Kontext besonders wichtig, weil saisonale Kampagnen, Neuheiten-Launches und Sortiments-Aktionen meist temporäre Boost-Phasen brauchen, die das Standard-Ranking überschreiben.
Cookieless ist kein Tradeoff
Eine häufige Sorge in der DACH-Region: GA4-basiertes Ranking braucht Cookies, ist also DSGVO-pflichtig und benötigt User-Consent. Diese Sorge ist berechtigt für klassische Personalisierungs-Ansätze, die pro User eine individuelle Ranking-Anpassung machen. Für ein behavior-getriebenes Ranking, das auf aggregierter Ebene arbeitet, ist sie unbegründet.
Der Unterschied liegt in der Aggregationsstufe. Klassische Personalisierung speichert pro User eine Profil-ID, ein Klick-Verlauf, eine Präferenzliste. Das ist tracking-basiert und consent-pflichtig. Ein Hybrid-Ranking auf Suchterm-Aggregat-Ebene speichert keine User-IDs. Es speichert nur, dass die Suchanfrage "Laufschuh Herren" historisch eine Klickrate von X Prozent auf Produkt A, Y Prozent auf Produkt B und so weiter hatte. Diese Aggregat-Daten enthalten keine personenbezogenen Informationen und sind damit nicht consent-pflichtig.
Operativ heißt das: ein Shop kann auch ohne CMP-Consent für GA4 ein behavior-getriebenes Ranking aufbauen, wenn die Aggregation serverseitig erfolgt und die Daten auf Aggregat-Ebene gespeichert werden. Die Datenquelle kann auch eine alternative Server-Side-Tracking-Pipeline sein, die ohne Browser-Cookies arbeitet.
Das AI Data Discovery Framework sorgt zusätzlich dafür, dass die behavioralen Signale auf Suchterm-Cluster-Ebene aggregiert werden. Damit verteilt sich der Signal-Effekt auf semantisch ähnliche Suchanfragen und einzelne Suchterme mit niedrigem Volumen profitieren von den Signalen ihrer Cluster.
Für DACH-Shops, die regelmäßig DSGVO-Audits durchlaufen, ist dieser Punkt nicht nur juristisch relevant, sondern auch ein direktes Trust-Signal in der Customer Communication. Wer behavior-getriebenes Ranking ohne User-Tracking anbietet, kann das im Cookie-Banner und in der Datenschutz-Erklärung aktiv ausspielen.
A/B-Test-Setup: NDCG, MRR und das echte Business-Metrik
Ranking-Änderungen ohne strukturierte A/B-Tests sind Geschmackssache. Mit Tests sind sie eine messbare Disziplin. Fünf Metriken sind in unseren Audits die zuverlässigsten Indikatoren.
NDCG (Normalized Discounted Cumulative Gain) misst, wie gut die Reihenfolge der Trefferliste mit der idealen Reihenfolge übereinstimmt. Werte zwischen 0 und 1, höher ist besser. NDCG braucht eine Ground-Truth-Bewertung pro Treffer, in der Praxis abgeleitet aus Klickdaten oder Conversion-Daten. NDCG@5 (also nur die ersten fünf Treffer) ist im E-Commerce die aussagekräftigste Variante, weil Kunden selten weiter scrollen.
MRR (Mean Reciprocal Rank) misst die durchschnittliche Position des ersten gekauften Produkts in der Trefferliste. Werte näher an 1 sind besser. Ein MRR von 0,25 heißt, dass der erste Kauf im Durchschnitt auf Position 4 liegt. MRR ist besonders nützlich, um Conversion-relevante Ranking-Änderungen zu bewerten.
Suggest-to-Cart-Rate misst, wie viele Suchanfragen am Ende zu einem Warenkorb-Eintrag führen. Diese Metrik ist die direkte Brücke zwischen Such-Performance und Umsatz. Gesunde Werte liegen bei 12 bis 25 Prozent, abhängig vom Sortiment.
Average Order Value (AOV) aus Search-Sessions zeigt, ob die Such-Verbesserung höherwertige Käufe ermöglicht oder nur die Stückzahl-Conversion treibt. Wenn das neue Ranking nur Discount-Artikel nach oben bringt, sinkt der AOV, auch wenn die Conversion-Rate steigt.
Search Revenue per Session ist die ultimative Business-Metrik. Sie kombiniert Klickrate, Conversion-Rate und AOV in eine einzige Zahl. Wer diese Zahl pro Variante in einem A/B-Test sauber misst, hat den ehrlichsten Vergleich.
Ein sauberer A/B-Test für Ranking-Änderungen verlangt drei Bedingungen.
Erstens: konsistente User-Bucketisierung pro Session. Ein User darf in einer Session nicht zwischen Variante A und Variante B wechseln, sonst werden die Daten unbrauchbar.
Zweitens: ausreichendes Datenvolumen pro Variante. Faustregel: mindestens 10.000 Suchanfragen pro Variante über mindestens zwei Wochen. Bei kleineren Shops dauert der Test länger oder die statistische Aussagekraft sinkt.
Drittens: Kontrolle für saisonale Effekte. Ein Test über einen Saisonwechsel (etwa von Frühjahr zu Sommer) verfälscht die Daten massiv. Lange Tests sollten innerhalb einer Saison liegen oder die Saisonalität explizit modellieren.
Ein konkretes Conversion-Beispiel aus einem Kundenprojekt: ein DACH-Shop mit 42.000 Produkten ergänzte sein klassisches BM25-Ranking um eine GA4-basierte Behavior-Schicht mit Recency-Gewichtung. Effekt nach acht Wochen: NDCG@5 stieg von 0,42 auf 0,61, MRR stieg von 0,21 auf 0,34, die Search Revenue per Session legte um 18 Prozent zu. Kein Sortiment wurde verändert, keine Marketing-Aktion lief parallel.
Was Sie diese Woche tun können
Nicht jeder Shop muss sofort auf eine Hybrid LLM Search migrieren, um das Ranking zu verbessern. Wenn Sie mit einer klassischen Suche arbeiten, lohnt sich diese Reihenfolge.
Schritt 1: GA4-Event-Tracking prüfen. Stellen Sie sicher, dass die sieben relevanten Events (view_item, select_item, add_to_cart, begin_checkout, purchase, view_search_results, search) sauber implementiert sind und der Suchterm pro Event ausgespielt wird. Ohne diesen Datenfluss kein behavior-getriebenes Ranking.
Schritt 2: Top-100-Suchanfragen analysieren. Welche Suchbegriffe machen 80 Prozent Ihres Such-Volumens aus? Wo liegt das tatsächlich konvertierende Produkt in der Trefferliste? Wenn der Bestseller nicht in den Top 3 steht, haben Sie das Pain-Muster, das dieser Artikel beschreibt.
Schritt 3: Behavior-Boost manuell pflegen. Als Zwischenschritt zu einer automatisierten Pipeline können Sie für die Top-30 Suchanfragen manuelle Promotion-Regeln im Such-Backend setzen. Das ist nicht skalierbar, schließt aber kurzfristig die größten Lücken.
Schritt 4: Recency-Boost für Neuheiten konfigurieren. Geben Sie neuen Produkten einen 30-Tage-Sichtbarkeits-Bonus. Damit lösen Sie das Cold-Start-Problem zumindest für aktive Sortimentspflege.
Schritt 5: A/B-Test-Infrastruktur aufbauen. Ohne saubere Bucketisierung können Sie keine Ranking-Änderungen messbar bewerten. Investieren Sie eine Sprint in das Test-Setup, bevor Sie das nächste Ranking-Experiment starten.
Schritt 6: NDCG@5 und MRR im wöchentlichen Reporting verankern. Diese beiden Metriken sind die Standard-Indikatoren für Ranking-Qualität. Wenn sie nicht im Reporting sind, fliegen Sie blind.
Diese sechs Schritte können Sie auch dann gehen, wenn Sie später auf eine Hybrid LLM Search wechseln. Die Erkenntnisse aus den GA4-Analysen und der A/B-Test-Pipeline helfen bei jeder Migration. Was sie nicht ersetzen können, ist die automatisierte dreischichtige Score-Komposition, die eine echte Hybrid-Ranking-Architektur mitbringt. Eine vertiefte GA4-Integration werden wir in einem späteren Beitrag dieser Serie behandeln, der die konkrete Pipeline-Architektur und die Aggregations-Logik im Detail zeigt.
Häufige Fragen (FAQ)
Was ist BM25 und reicht es als Ranking-Algorithmus für E-Commerce?
BM25 ist seit 1994 der etablierte Standard-Algorithmus für textbasiertes Ranking in Suchmaschinen und Such-Bibliotheken wie Elasticsearch, OpenSearch und Solr. Er berechnet einen Relevanz-Score aus der Verteilung der Suchwörter im Dokument, gewichtet seltene Begriffe stärker und normalisiert die Dokumentlänge. Als Grundlage für E-Commerce-Ranking ist BM25 brauchbar, als alleinige Ranking-Logik aber zu schwach. Er kennt keine Conversion-Signale, keine Saison-Effekte, keine Lagerbestände und keinen User-Intent. In der Praxis bedeutet das: Bestseller verschwinden in der zweiten Reihe, wenn ihr Titel nicht keyword-dicht genug ist. Eine moderne Shop-Suche kombiniert BM25 mit einer Behavior-Schicht (GA4-Signale) und einer semantischen Schicht (Vektorsuche und LLM-Intent).
Was sind die Nachteile von BM25 in der Shop-Suche?
Drei strukturelle Schwächen treten in der E-Commerce-Praxis besonders hervor. Erstens: BM25 ist anfällig für Keyword-Stuffing, weil mehr Vorkommen eines Suchwortes den Score erhöhen. Wer im Produkttitel "Laufschuh Herren Sneaker Sport Running" schreibt, ranked höher als ein nüchterner Titel mit höherer Conversion-Rate. Zweitens: BM25 kann keine Synonyme erkennen. "Pullover" und "Sweater" sind für BM25 verschiedene Begriffe, sofern sie nicht manuell als Synonyme gepflegt werden. Drittens: BM25 hat keine Verhaltenssignale. Welches Produkt am besten konvertiert, weiß der Algorithmus nicht. Genau diese drei Schwächen führen dazu, dass eine reine BM25-Suche in mittleren bis großen Sortimenten in der Conversion-Rate hinter einer Hybrid-Suche zurückbleibt.
Wie unterscheidet sich BM25 von Vektorsuche?
BM25 arbeitet lexikalisch. Er matched Wörter gegen Wörter und ist damit auf exakte oder fast-exakte Token-Übereinstimmung angewiesen. Vektorsuche arbeitet semantisch. Sie repräsentiert sowohl die Suchanfrage als auch die Produkte als hochdimensionale Vektoren in einem Embedding-Raum und berechnet die Nähe der beiden Vektoren. Damit erkennt sie semantische Verwandtschaft zwischen "Pullover" und "Sweater" oder zwischen "Sneaker" und "Turnschuhe", ohne dass diese Beziehungen manuell gepflegt werden müssen. Vektorsuche ist BM25 in vielen E-Commerce-Szenarien überlegen, hat aber eigene Schwächen: sie ist teurer in der Indexierung, schwerer debuggbar und neigt bei sehr spezifischen Suchanfragen (Artikelnummern, exakte Modellnamen) zu schwächeren Ergebnissen. Die beste Kombination ist eine hybride Schicht: Vektorsuche für semantische Treffer, BM25 für exakte Token-Matches, beide Scores gewichtet kombiniert.
Was ist Learning to Rank im E-Commerce?
Learning to Rank ist ein maschinelles Lernverfahren, das aus historischen Click- und Conversion-Daten eine Ranking-Funktion lernt. Statt eine feste Score-Formel zu definieren, trainiert ein Modell darauf, welche Reihenfolge der Trefferliste in der Vergangenheit zu den höchsten Conversion-Raten geführt hat. Learning to Rank gehört zur Familie der überwachten Lernverfahren und nutzt Features wie BM25-Score, Klickrate pro Suchterm, Add-to-Cart-Rate, Verfügbarkeit, Preis und Marken-Affinität. Im E-Commerce ist Learning to Rank ein etablierter Ansatz für die zweite Ranking-Phase: nach einer groben Vorsortierung durch BM25 oder Vektorsuche ranked das LTR-Modell die Top-Treffer feinjustiert auf maximale Conversion. Das verlangt eine saubere Trainingsdaten-Pipeline und kontinuierliches Modell-Retraining.
Welche GA4-Signale gehören ins Ranking?
Sieben Events sind besonders wertvoll. view_item trackt Produktaufrufe und liefert die Click-Through-Rate pro Suchterm. select_item trackt Klicks aus Listenansichten und ist das primäre Signal für CTR-basiertes Ranking. add_to_cart zeigt, welche Produkte in den Warenkorb gelegt werden. begin_checkout und purchase sind die Conversion-Signale. view_search_results und search liefern den Kontext der Suchanfragen selbst. Diese sieben Events aggregiert pro Suchterm ergeben die Datenbasis für ein behavior-getriebenes Ranking. Aggregat-Ebene heißt: keine User-IDs, nur Suchterm-Statistiken. Damit ist die Aggregation DSGVO-konform und consent-arm.
Wie löst man das Cold-Start-Problem für neue Produkte?
Drei Strategien lassen sich kombinieren. Embedding-Vererbung überträgt den Behavior-Score ähnlicher bestehender Produkte auf das neue Produkt, sodass es nicht im Ranking absinkt. Boost-Phase gibt neuen Produkten in den ersten 14 oder 30 Tagen einen Sichtbarkeits-Bonus, sodass sie Klick-Daten sammeln können. Sortimentsgruppen-Daten initialisieren das neue Produkt mit dem Durchschnitt seiner Kategorie. Eine Hybrid-Ranking-Architektur kombiniert alle drei automatisch, ohne dass die Produktpflege jeden neuen Artikel manuell boosten muss. Ohne diese Strategien zementiert ein behavior-getriebenes Ranking die bestehenden Bestseller und blockiert Sortiments-Neuheiten.
Wie testet man Ranking-Änderungen A/B-sauber?
Drei Bedingungen sind kritisch. Erstens: konsistente User-Bucketisierung pro Session, sodass ein User nicht zwischen Variante A und B wechselt. Zweitens: ausreichendes Datenvolumen, typisch mindestens 10.000 Suchanfragen pro Variante über mindestens zwei Wochen. Drittens: Kontrolle für Saison-Effekte, ein Test darf nicht über einen Sortimentswechsel oder eine Marketing-Aktion laufen. Als Metriken eignen sich NDCG@5 für die Ranking-Qualität, MRR für die Position des ersten Kaufs und Search Revenue per Session als ultimative Business-Metrik. Wer diese drei Metriken pro Variante misst, hat den ehrlichsten Vergleich und kann saubere Ranking-Entscheidungen treffen.
Bereit für ein Ranking, das verkauft statt nur zu matchen?
Textscore, GA4-Behavior, semantische Intent-Erkennung und Recency-Gewichtung sind die vier Stellschrauben, die in der Praxis über die Conversion-Wirkung Ihrer Shop-Suche entscheiden. Wer nur Textscore hat, lässt die hälfte des möglichen Umsatzes liegen. Wer alle vier Schichten gewichtet kombiniert, gewinnt zweistellige Conversion-Lifts. Volt Search® von BatteryIncluded kombiniert klassisches Token-Matching, Vektorsuche, LLM-basierte Intent-Verarbeitung und GA4-Behavior-Aggregation in einer entkoppelten Infrastruktur. Finden statt Suchen, cookieless, DSGVO-konforme KI, Made in Germany, ohne dass Sie eine eigene Ranking-Pipeline aufbauen oder einen Search-Engineer einstellen müssen.
Auch der direkte Conversion-Effekt ist in Kundenprojekten dokumentiert:
"Seit wir BatteryIncluded einsetzen, sehen wir spürbare Verbesserungen: bereits nach zwei Monaten stieg unsere Conversion Rate um 10 Prozent, und nach vier Monaten konnten wir einen Zuwachs von 19 Prozent verzeichnen."
B&W Handelsgesellschaft mbH
Zu Ihrer kostenlosen Demo und erleben Sie live an Ihren eigenen Produktdaten, wie Volt Search® den Bestseller auf Platz 1 bringt und wie aus reiner Textmatch-Logik eine smarte Listing-Engine wird, die Conversion-Daten direkt im Ranking nutzt. Ohne eigenes Cluster, ohne User-Tracking, ohne lange Setup-Phase.