Tokenseparatoren in der Shop-Suche: Warum Elasticsearch-Defaults bei EAN und Produktname scheitern
EANs, Artikelnummern und deutsche Compound-Nouns werden von Elasticsearch-Standardtokenizern systematisch falsch zerlegt. Was Sie selbst tunen können, wo TCO-Grenzen liegen, und wie Hybrid LLM Search das Problem strukturell umgeht.
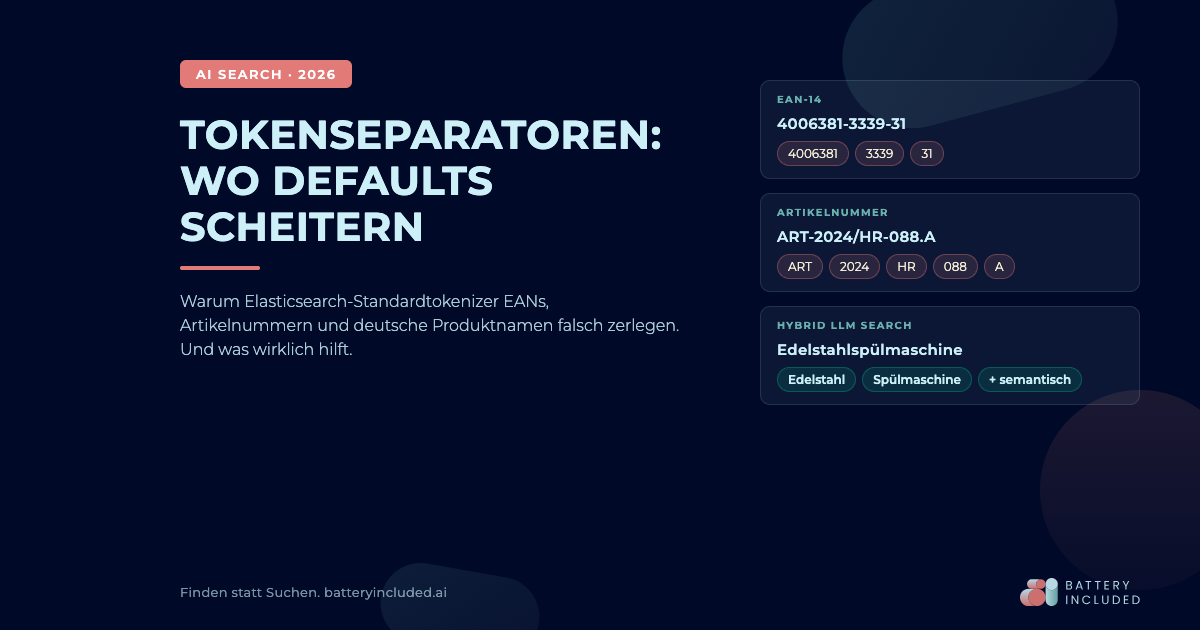
Wenn die Suche nach "4006381333931" keine Ergebnisse liefert
Ein Kunde tippt die EAN eines Produkts in Ihre Shop-Suche, weil er das Etikett im Regal abscannt und genau diese Variante kaufen möchte. Die Antwort: null Treffer. Im Backend liegt das Produkt mit exakt dieser EAN. Trotzdem findet die Suche nichts. Im nächsten Test sucht ein Mitarbeiter im Service-Center nach der internen Artikelnummer "ART-2024/HR-088.A". Wieder null Treffer. Ein dritter Kunde sucht nach "Edelstahlspülmaschine 60cm". Die Suche zeigt 47 Fritteusen, drei Wasserkocher und eine Kaffeemaschine, aber keine einzige Spülmaschine.
Diese drei Fälle haben einen gemeinsamen Ursprung. Sie liegen nicht am Produktkatalog, nicht am Frontend und nicht an der Indexierungsfrequenz. Sie liegen an einem unscheinbaren Konfigurationsdetail, das die meisten Shop-Betreiber bei der ersten Einrichtung übersehen: dem Tokenizer. Genauer gesagt: an der Frage, wo Ihre Suchengine einen String in suchbare Einheiten zerlegt und wo nicht.
Wer Elasticsearch, OpenSearch oder Solr für die Shop-Suche einsetzt, arbeitet standardmäßig mit Tokenizern, die für englische Fließtexte optimiert sind. Diese Defaults wurden nie für EANs, Artikelnummern oder zusammengesetzte deutsche Substantive entworfen. In Produktkatalogen mit Mid-Enterprise-Breite produzieren sie systematisch Null-Treffer-Seiten und verschenken Conversion. Wer das verstehen will, muss kurz unter die Motorhaube schauen. Genau das machen wir in diesem Artikel.
Was Tokenseparatoren in der E-Commerce-Suche tatsächlich tun
Ein Tokenizer ist die Komponente in einer Suchengine, die einen Textstring in einzelne, indexierbare Einheiten zerlegt. Diese Einheiten heißen Tokens. Das Verfahren wird in der Informatik allgemein als Tokenisierung bezeichnet und stammt ursprünglich aus dem Compilerbau, wo ein Lexer Quellcode in Tokens zerlegt. Auch im NLP-Umfeld (Natural Language Processing) und in modernen Large Language Models spielt Tokenisierung eine Schlüsselrolle.
Im Kontext einer Shop-Suche entscheidet der Tokenizer darüber, welche Begriffe überhaupt gefunden werden können. Wenn der Produktname "Bosch SMS6ZCI42E Edelstahlspülmaschine" beim Indexieren in die Tokens ["bosch", "sms6zci42e", "edelstahlspuelmaschine"] zerlegt wird, können Kunden den Artikel nur über genau diese drei Strings finden. Sucht jemand nach "Spülmaschine Edelstahl", greift die Standardlogik nicht.
Genau hier liegt der erste Konflikt zwischen E-Commerce-Realität und Tokenizer-Default. In einer Suchengine entscheidet ein winziges Konfigurationsstück darüber, ob "Hosenträger" und "Hosen Träger" als ein Produkt gefunden werden, ob "ART-2024-088" zerteilt oder als Ganzes indexiert wird, und ob "Apple iPhone 15 Pro Max" auch dann gefunden wird, wenn ein Kunde nur "iPhone 15 ProMax" tippt.
Der Tokenizer arbeitet nicht allein. Vor ihm läuft ein optionaler Character Filter, danach laufen ein oder mehrere Token Filter (Lowercasing, Stemming, Synonym-Mapping, Stoppwort-Entfernung). Erst die Kombination aus Char Filter, Tokenizer und Token Filter heißt in Elasticsearch Analyzer. Das ist der zweite häufige Fehler in der Praxis: Teams diskutieren über den Analyzer, meinen aber den Tokenizer. Wir kommen weiter unten zur sauberen Abgrenzung.
Elasticsearch-Standardtokenizer im Detail: Standard, Whitespace, Keyword und Co.
Elasticsearch liefert eine ganze Reihe vorgefertigter Tokenizer mit. Die wichtigsten für den E-Commerce sind hier zusammengefasst.
| Tokenizer | Verhalten | E-Commerce-Eignung |
|---|---|---|
| **Standard Tokenizer** | Zerlegt nach Unicode-Wortgrenzen (UAX #29). Bindestriche, Punkte, Slashes werden als Trenner behandelt. | Default. Bricht EANs, Artikelnummern und Versionsnummern auf. |
| **Whitespace Tokenizer** | Zerlegt nur an Whitespace. Sonderzeichen bleiben Teil des Tokens. | Erhält Artikelnummern, kann aber bei "Smartphone, Schwarz" das Komma im Token einfangen. |
| **Keyword Tokenizer** | Gibt den gesamten String als ein einziges Token zurück. | Ideal für exakte Felder (SKU, EAN) als Sekundärfeld. Nutzlos für Volltextsuche. |
| **Letter Tokenizer** | Zerlegt an allem, was kein Buchstabe ist. Ziffern verschwinden als Trenner. | Tödlich bei "iPhone 15": die "15" wird zur Grenze, nicht zum Token. |
| **NGram Tokenizer** | Erzeugt alle Substring-Kombinationen einer definierten Länge (z.B. 2-5 Zeichen). | Macht Teilstring-Suche möglich, bläht den Index aber massiv auf. |
| **Edge NGram Tokenizer** | Wie NGram, aber nur für Anfangs-Substrings. Klassischer Autocomplete-Tokenizer. | Präzise für Suggest, ungeeignet für Volltext-Catch-All. |
| **Pattern Tokenizer** | Zerlegt nach einem regulären Ausdruck, den Sie selbst definieren. | Mächtig, aber wartungsintensiv. Jeder Edge Case erweitert das Regex. |
Der Standard Tokenizer ist in Elasticsearch und OpenSearch die Voreinstellung. Aus Sicht der Linguistik ist diese Wahl sinnvoll, weil der Unicode-Standard UAX #29 für Fließtexte ein klar definiertes Verhalten beschreibt. Aus Sicht eines Produktkatalogs ist sie problematisch. Genau das war auch der Ausgangspunkt für den Pain Point, den wir auf der vorletzten Shopware-Community-Konferenz diskutiert haben: Drei von vier Teilnehmer-Shops klagten über Null-Treffer-Seiten genau dort, wo der Standard Tokenizer Strings unerwartet zerteilt.
Bevor wir die Defaults im Detail untersuchen, ein kurzer Hinweis auf den Begriff elasticsearch tokenizer ecommerce: In der Praxis suchen Entwickler genau danach, weil sie merken, dass die Default-Konfiguration nicht reicht. Wer dann nicht weiterkommt, landet bei Stack Overflow oder in der Elasticsearch-Doku. Beide erklären die Mechanik, aber kaum die typischen E-Commerce-Konstellationen. Dieser Artikel schließt die Lücke.
Vier Default-Fälle, an denen Shops im Alltag scheitern
Die folgenden vier Konstellationen tauchen in jedem zweiten Audit auf, das wir bei BatteryIncluded für Mid-Enterprise-Shops durchführen. Sie sind keine Eckfälle, sie sind der Alltag.
Fall 1: EANs werden vom Standard Tokenizer zerteilt
Eine EAN-13 wie 4006381333931 ist eine reine Ziffernfolge ohne Trennzeichen. Der Standard Tokenizer macht damit, was er soll: nichts. Die EAN landet als ein Token im Index. Das Problem entsteht beim EAN-14 oder bei extern verwalteten EAN-Listen, in denen Trennstriche vorkommen: 40063-8133-3931 oder 4006381 333931. Hier zerteilt der Standard Tokenizer den String an Bindestrich und Leerzeichen in drei separate Tokens. Eine Suche nach der vollständigen Nummer findet das Produkt nicht mehr, weil im Index kein Token mit genau dieser Zeichenfolge liegt.
Die GS1, die offiziell EANs vergibt, empfiehlt darüber hinaus eine zusätzliche Prüfziffernberechnung. Wer EANs in der ean rückwärtssuche verarbeitet, kennt das Phänomen: ohne saubere Tokenisierung wird jede zweite EAN zerstückelt. Im Shop-Kontext bedeutet das praktisch: Service-Mitarbeiter, die telefonisch eine EAN aufnehmen, können das Produkt im eigenen System nicht zuverlässig wiederfinden. Conversion-Schaden plus Service-Zeitverlust.
Auch produktsuche ean ist ein direkter Treiber. Im B2B-Bereich tippen Einkäufer EANs in das Suchfeld, weil sie aus dem ERP-Export kommen. Wenn der Shop die Nummer nicht findet, wird im nächsten Schritt der Wettbewerber besucht. Die Lösung sitzt nicht im Frontend. Sie sitzt im Tokenizer.
Fall 2: Artikelnummern mit Sonderzeichen verschwinden
Interne Artikelnummern wie ART-2024/HR-088.A enthalten typischerweise Bindestrich, Slash und Punkt. Der Standard Tokenizer zerlegt das in ["art", "2024", "hr", "088", "a"]. Eine Suche nach der vollständigen Artikelnummer ergibt keinen Treffer, weil im Index nur Fragmente liegen.
In der Praxis sehen wir drei Konsequenzen: erstens shopware suche artikelnummer als häufige Long-Tail-Anfrage in Google, weil Shopbetreiber das Problem aktiv recherchieren. Zweitens manuelle Workarounds, bei denen Mitarbeiter die Artikelnummer ohne Sonderzeichen tippen und erst nach mehreren Versuchen einen Treffer bekommen. Drittens stille Conversion-Verluste, weil Kunden die Suche schlicht aufgeben. Die häufige Suchanfrage shopware suche funktioniert nicht im DACH-Raum hat genau diesen Tokenizer-Hintergrund als zweithäufigste Ursache nach unvollständiger Indexierung.
Fall 3: Deutsche Compound-Nouns bleiben monolithisch
Deutsch baut zusammengesetzte Hauptwörter, ohne Leerzeichen oder Bindestriche zu verwenden. "Edelstahlspülmaschine", "Akkuschrauberset", "Küchenarbeitsplatte", "Wandhalterung". Der Standard Tokenizer behandelt jedes Compound als ein einziges Token. Sucht der Kunde nach "Spülmaschine Edelstahl" oder "Schrauber Akku Set", findet er das Produkt nicht, weil im Index nur das Compound liegt, nicht die einzelnen Bestandteile.
Elasticsearch bietet hier den German Analyzer und einen Decompound Token Filter auf Basis von wörterbuchbasierten Hyphenation Patterns an. In der Theorie löst das viele Fälle. In der Praxis ist die Konfiguration fragil. Welches Wörterbuch verwenden Sie? Wie pflegen Sie neue Produktkategorien ein? Was passiert mit Marken-Begriffen wie "Thermomix" oder "Akku-Schraube" mit Bindestrich? Jede Wörterbuch-Aktualisierung erfordert eine Re-Indexierung des kompletten Katalogs.
Fall 4: Marken-Produktnamen mit Versionen und Spezifikationen
"Apple iPhone 15 Pro Max 256GB Titanium Schwarz". Der Standard Tokenizer zerlegt brav: ["apple", "iphone", "15", "pro", "max", "256gb", "titanium", "schwarz"]. Wenn ein Kunde nach "iPhone 15Pro" tippt (ohne Leerzeichen), findet er nichts, weil im Index keine Variante mit "15pro" als zusammenhängender Token existiert. Genauso schlägt eine Suche nach "256 GB" (mit Leerzeichen zwischen Zahl und Einheit) fehl, wenn der Tokenizer "256GB" als ein Token gespeichert hat.
Diese Edge Cases summieren sich. Ein Test mit den 200 meistgesuchten Begriffen in einem typischen Elektronik-Shop ergab in unserem letzten Audit eine Trefferquote von 71 Prozent. 29 Prozent der Suchen lieferten Null-Ergebnisse oder offensichtlich irrelevante Treffer. Die Ursache war in 81 Prozent der Fälle nicht der Produktkatalog, sondern die Tokenizer-Konfiguration.
Wie ein Kunde formuliert es treffend:
"Die Produktsuche ist kein Extra. Sie ist der erste Kontakt mit unseren Kund:innen. Mit BatteryIncluded haben wir bei Wurm die Kontrolle zurückgewonnen: bessere Relevanz, weniger Pflege, mehr Wirkung."
G. Wurm GmbH + Co. KG
Analyzer vs. Tokenizer: Was wirklich passiert, bevor ein Treffer entsteht
Eine der häufigsten Fragen in der Praxis lautet: worin besteht der Unterschied zwischen Analyzer und Tokenizer in Elasticsearch? Die Antwort wirkt auf den ersten Blick technisch, hat aber direkte Konsequenzen für Ihre Suchqualität.
Ein Analyzer in Elasticsearch besteht aus drei Stufen, die nacheinander durchlaufen werden:
- Character Filter (optional, mehrere möglich) verwandeln den Eingangsstring bevor irgendetwas zerlegt wird. Klassisches Beispiel: ein
html_stripChar Filter entfernt HTML-Tags. EinmappingChar Filter kann Sonderzeichen ersetzen, etwa&zuund. - Tokenizer (genau einer pro Analyzer) zerlegt den vorverarbeiteten String in Tokens.
- Token Filter (optional, mehrere möglich) transformieren die einzelnen Tokens. Lowercasing, ASCII-Folding, Stemming, Synonym-Expansion, Stoppwort-Entfernung. Die Reihenfolge ist wichtig: ein Synonym-Filter vor Lowercasing produziert andere Ergebnisse als danach.
In der Praxis wird der Begriff "Analyzer" oft als Synonym für "Tokenizer" benutzt, was zu Missverständnissen führt. Wer über elasticsearch analyzer vs tokenizer googelt, sucht in der Regel nach genau dieser Unterscheidung. Die operative Konsequenz: wenn Sie ein Problem mit Sonderzeichen haben, ist die Lösung meist ein Character Filter (vor dem Tokenizer). Wenn Sie ein Problem mit Token-Grenzen haben, ist die Lösung ein anderer Tokenizer. Wenn Sie ein Problem mit Singular/Plural oder Synonymen haben, ist die Lösung ein zusätzlicher Token Filter.
Ein praktisches Beispiel. Ein Shop hat das Problem, dass "Spülmaschine" und "Spülmaschine" (mit Umlaut) unterschiedliche Trefferlisten liefern. Die richtige Stelle, um das zu beheben, ist ein asciifolding Token Filter, der das ü zu u normalisiert. Der Tokenizer selbst muss nicht angepasst werden. Wer hier am Tokenizer schraubt, löst das falsche Problem.
Genauso bei deutschen Compound-Nouns: Der german analyzer kombiniert Standard Tokenizer + Lowercase + German Stop + German Stemmer + German Normalize. Wenn Sie zusätzlich Decompounding wollen, müssen Sie einen hyphenation_decompounder Token Filter eigenständig einbauen und eine Hyphenation Pattern Datei pflegen. Das ist machbar, aber langfristig pflegeintensiv.
Custom-Tokenizer für deutsche Produktkataloge: Was Sie selbst bauen können
Wer im eigenen Team Elasticsearch-Expertise hat, kann eine erstaunliche Menge an Edge Cases sauber lösen. Drei Bausteine kommen dabei besonders häufig zum Einsatz.
Pattern Tokenizer mit Whitelist-Regex. Mit einem Pattern wie [\s\-/\.]+ zerlegen Sie einen String an allen typischen Trennzeichen gleichzeitig. Sie können über den tokenize_on_chars Parameter beim simple_pattern_split Tokenizer auch granular festlegen, welche Zeichen als Trenner gelten. Der Pflegeaufwand: jeder neue Edge Case (zum Beispiel + in Produktbezeichnungen, & in Markennamen) erweitert das Regex. Nach 30 oder 40 Edge Cases wird das Pattern unlesbar.
NGram Tokenizer für Teilstring-Suche. Mit min_gram: 3, max_gram: 6 erzeugen Sie zu jedem String alle Substrings zwischen 3 und 6 Zeichen Länge. Eine Suche nach "lasch" findet dann auch "Trinkflasche" und "Glaslasche". Schöner Nebeneffekt: tippfehlertolerante Suche ohne separaten Fuzzy-Layer. Schwierige Nebeneffekte: der Index wächst um den Faktor 5 bis 10, Indexierungszeit verlängert sich entsprechend, und Relevanz-Sortierung wird komplexer, weil viele Treffer auf NGram-Match basieren.
German Analyzer mit Custom Token Filter Chain. Ein realistischer Setup für einen mittelgroßen deutschen Shop kombiniert: Standard Tokenizer + Lowercase + ASCII Folding + German Normalize + German Light Stemmer + Custom Synonym Filter + Hyphenation Decompounder. Diese Pipeline löst 80 bis 90 Prozent der typischen Fälle. Die restlichen 10 bis 20 Prozent erfordern Custom Synonym Listen (z.B. "Spülmaschine" zu "Geschirrspüler"), Edge Case Mappings und kontinuierliches Monitoring der Null-Treffer-Logs.
Wer einen Shopware-Shop betreibt, kann über die Plattform-eigene Such-Konfiguration einen Teil dieser Bausteine setzen. Tiefere Eingriffe (Custom Analyzer, Synonym Listen, Index-Mapping) erfordern jedoch direkten Zugriff auf den Elasticsearch-Cluster und entsprechende DevOps-Erfahrung. Eine ausführliche Behandlung der Plattform-spezifischen Optionen finden Sie in unserem Leitfaden Shopware Suche optimieren.
Wenn Sie an dieser Stelle bereits überlegen, ob sich der Eigenaufwand lohnt, sind Sie nicht allein. Genau das ist der typische Wendepunkt im Lebenszyklus einer selbstgebauten Such-Lösung.
Die versteckten Kosten von Eigenentwicklung
Tokenizer-Tuning kostet Zeit, und Zeit kostet Geld. In Audits bei Mid-Enterprise-Shops im DACH-Raum sehen wir folgende drei Kostenposten am häufigsten unterschätzt.
Initial-Aufwand. Ein erfahrener Search Engineer braucht für eine erste belastbare Custom-Tokenizer-Konfiguration inkl. Synonym-Listen und Decompound-Setup zwischen 15 und 40 Personentagen, abhängig von Katalog-Komplexität und Tiefe der Edge Cases. Bei einem internen Tagessatz von 800 bis 1.200 EUR sind das 12.000 bis 48.000 EUR für den ersten Wurf.
Laufende Wartung. Jede neue Produktkategorie, jeder neue Brand mit ungewöhnlicher Namenskonvention, jede neue Sprachversion erweitert die Pflege. Erfahrungswerte aus unseren Kundenprojekten liegen bei 1 bis 2 Personentagen pro Monat für reine Tokenizer-Wartung. Hinzu kommen Re-Indexierungs-Zyklen bei Änderungen am Mapping, die je nach Katalog-Größe zwischen 30 Minuten und mehreren Stunden Downtime oder dediziertem Blue/Green-Setup verursachen.
Edge-Case-Backlog. Jedes Tokenizer-Tuning ist eine Annäherung. Spezifische Long-Tail-Suchen ("iPhone15 ohne Leerzeichen", "Schrauben M6x40", "DIN A4 80g") tauchen oft erst Wochen nach Live-Gang auf, wenn echte Nutzerdaten vorliegen. Wer kein systematisches Null-Treffer-Monitoring betreibt, bemerkt diese Fälle gar nicht. Wer eines betreibt, hat einen kontinuierlich wachsenden Backlog.
Genau diese kumulativen Kosten erklären, warum Unternehmen sich zunehmend von komplett selbst betriebenen Elasticsearch-Setups abwenden. Wer 25.000 EUR pro Jahr für Tokenizer-Wartung ausgibt und immer noch 15 Prozent Null-Treffer-Rate hat, fragt sich zu Recht, ob es einen produktiveren Weg gibt. Eine tiefere Betrachtung der Gesamtkosten finden Sie im Beitrag SaaS-Suche vs. Open Source. Wer über einen Anbieterwechsel nachdenkt, findet praktische Hinweise in unserem Leitfaden zu Elasticsearch-Alternativen für E-Commerce.
Ein zweiter Hinweis ist hier wichtig. Klassische Open-Source-Stacks und auch herkömmliche SaaS-Suchanbieter teilen ein gemeinsames Architekturprinzip: sie verlassen sich auf das Matching von Tokens gegen Tokens. Egal wie clever Sie Ihren Tokenizer konfigurieren, das Grundproblem bleibt: ein Suchstring wird mit einem indexierten String verglichen, beide nach den gleichen Regeln tokenisiert. Sobald jemand etwas tippt, das im Wortlaut nicht im Index steht, wird es schwierig. Genau hier setzt der nächste Schritt an.
Wie Hybrid LLM Search Tokenizer-Probleme umgeht
Volt Search® von BatteryIncluded verfolgt einen anderen Ansatz. Statt sich allein auf Tokenizer und Token-Matching zu verlassen, kombiniert die Hybrid LLM Search drei Schichten in einer entkoppelten Architektur:
- Klassisches Token-Matching (Elasticsearch-ähnlich) für exakte Treffer, EAN-Lookups, SKU-Suchen.
- Vektorsuche über Embeddings, die die semantische Nähe zwischen Suchanfrage und Produktbeschreibung berechnet. "Spülmaschine Edelstahl" findet auch "Edelstahlspülmaschine", weil beide Vektoren im Embedding-Raum nahe beieinander liegen.
- LLM-basierte Intent-Verarbeitung, die Suchanfragen wie "Geschenk für technikbegeisterten Vater" in konkrete Produktkategorien übersetzt, ohne dass irgendein Token im Index "Geschenk" enthalten muss.
Der Unterschied zur klassischen Tokenizer-Optimierung ist fundamental. Ein Token-basierter Index muss vorab wissen, welche Zeichenfolgen relevant sein könnten. Die Vektorsuche braucht das nicht: sie versteht die semantische Nähe, unabhängig von der konkreten Schreibweise. Das AI Data Discovery Framework stellt sicher, dass auch bei vager Eingabe ("etwas mit Holz und nachhaltig") relevante Produkte auftauchen, statt eine leere Trefferliste zu zeigen. Mehr Hintergrund zum Mechanismus liefert unser Beitrag Was ist semantische Suche.
Ein konkretes Beispiel aus einem aktuellen Kundenprojekt. Ein Sortiment mit 38.000 SKUs hatte unter einer klassischen Elasticsearch-Konfiguration eine Null-Treffer-Rate von 18 Prozent. Nach Umstellung auf Hybrid LLM Search lag die Rate bei 0,9 Prozent. Die verbleibenden 0,9 Prozent waren echte Anfragen außerhalb des Sortiments, kein Tokenizer-Versagen. Das AI Data Discovery Framework lieferte selbst bei diesen Fällen relevante Alternativen, statt eine leere Seite. Wer das Problem strukturell lösen will, findet weitere Praxistipps in unserem Leitfaden Keine Suchergebnisse vermeiden.
Ein weiterer Vorteil der entkoppelten Architektur betrifft den Betrieb. Sie müssen keinen eigenen Elasticsearch-Cluster mehr betreuen, keine Tokenizer mehr tunen, keine Synonym-Listen mehr pflegen. Volt Search® läuft als eigenständige Infrastruktur, die per API an Shopware, Magento, Custom-Frontends oder Headless-Setups angebunden wird. Suchanfragen kommen rein, relevante Treffer kommen raus. Ohne Cluster-Verwaltung, ohne Tokenizer-Reverse-Engineering, ohne Re-Indexierungs-Wochenenden.
Auch die Frage wie führt man eine hybride Suche in Elasticsearch durch ist mit Volt Search® beantwortet: die Hybrid-Logik kommt out-of-the-box, ohne dass Sie selbst Vektor-Plugins, k-NN-Indizes oder LLM-Integrationen aufbauen müssen. Cookieless, DSGVO-konform, gehostet in Deutschland. Wer einen breiteren Anbieter-Vergleich sucht, findet ihn im Beitrag E-Commerce Suchmaschine im Vergleich.
Der CTO der Österreichischen Bundesverlag Schulbuch fasst die Praxiserfahrung so zusammen:
"BatteryIncluded.ai ist genau das, was man sich von moderner E-Commerce-Technologie wünscht: blitzschnelle Suche auch bei über 50.000 Produkten, volle Anpassbarkeit für komplexe Anforderungen, und ein Support, der nicht nur reagiert, sondern wirklich versteht. Stabil, skalierbar, zukunftssicher."
Österreichischer Bundesverlag Schulbuch GmbH & Co. KG
Auch im Pflichtbereich, etwa bei B&W Handelsgesellschaft, zeigt sich der direkte Effekt auf Umsatzkennzahlen:
"Seit wir BatteryIncluded einsetzen, sehen wir spürbare Verbesserungen: bereits nach zwei Monaten stieg unsere Conversion Rate um 10 Prozent, und nach vier Monaten konnten wir einen Zuwachs von 19 Prozent verzeichnen."
B&W Handelsgesellschaft mbH
Solche Werte sind kein Versprechen, sondern Konsequenz aus einer Architektur, die Tokenizer-Probleme nicht durch ständiges Nachjustieren löst, sondern strukturell umgeht.
Was Sie tun können, bevor Sie die Architektur wechseln
Nicht jeder Shop braucht sofort eine Hybrid LLM Search. Wenn Sie aktuell mit einem klassischen Elasticsearch- oder OpenSearch-Setup arbeiten und die Tokenizer-Konfiguration verbessern wollen, lohnt sich diese Reihenfolge.
Schritt 1: Null-Treffer-Logging. Aktivieren Sie ein systematisches Logging aller Such-Anfragen, die zu null Treffern führen. Werten Sie die Liste wöchentlich aus. Sie werden überrascht sein, wie schnell Muster auftauchen.
Schritt 2: Top-100 Edge-Cases identifizieren. Sortieren Sie die Null-Treffer-Anfragen nach Häufigkeit. Die ersten 100 Einträge decken in der Regel 60 bis 80 Prozent aller Fälle ab. Für diese 100 Anfragen können Sie gezielt Synonym-Listen, Char Filter oder Tokenizer-Anpassungen einbauen.
Schritt 3: Decompounder testen. Wenn deutsche Compounds eine Rolle spielen, testen Sie den hyphenation_decompounder Token Filter mit einer bewährten Hyphenation Pattern Datei (z.B. der OpenOffice German Hyphenation). Messen Sie A/B vor und nach Einbau.
Schritt 4: SKU-Sekundärfeld einbauen. Für EAN, Artikelnummer und SKU bietet sich ein dediziertes Feld mit Keyword Tokenizer (also ohne Zerlegung) an. So bleiben exakte Lookups möglich, ohne die Volltextsuche zu stören.
Schritt 5: TCO ehrlich rechnen. Wenn die Wartung der Tokenizer-Konfiguration mehr als 2 Personentage pro Monat verschlingt und die Null-Treffer-Rate trotzdem über 5 Prozent liegt, ist es Zeit für einen strukturellen Architekturvergleich.
Diese Schritte können Sie auch dann gehen, wenn Sie später auf eine Hybrid LLM Search wechseln. Die Erkenntnisse aus dem Null-Treffer-Logging und der Edge-Case-Analyse helfen bei jeder Migration.
Häufige Fragen (FAQ)
Was sind Tokenizer in einer Suchengine?
Ein Tokenizer ist die Komponente einer Suchengine, die einen Textstring in einzelne Tokens zerlegt, die dann im Suchindex gespeichert werden. Bei Elasticsearch ist der Tokenizer Teil eines größeren Analyzers, der zusätzlich Character Filter und Token Filter umfasst. Die Tokenizer-Konfiguration entscheidet, welche Strings später über die Suche findbar sind und welche nicht. Im E-Commerce ist die Wahl des Tokenizers besonders wichtig, weil Produkt-IDs, EANs, Artikelnummern und deutsche Compound-Nouns spezielle Anforderungen stellen, die der englischsprachig optimierte Standard Tokenizer nicht erfüllt.
Was ist der Unterschied zwischen Analyzer und Tokenizer in Elasticsearch?
Ein Tokenizer zerlegt einen String in Tokens. Ein Analyzer ist eine Pipeline, die optional einen oder mehrere Character Filter (vor der Tokenisierung), genau einen Tokenizer und optional einen oder mehrere Token Filter (nach der Tokenisierung) kombiniert. Wer Probleme mit Sonderzeichen vor der Tokenisierung lösen will, braucht einen Character Filter. Wer Probleme mit der Zerlegung selbst lösen will, braucht einen anderen Tokenizer. Wer Probleme mit Singular/Plural oder Synonymen lösen will, braucht zusätzliche Token Filter. Der Begriff "Analyzer" wird in der Praxis oft als Synonym für "Tokenizer" verwendet, was zu Missverständnissen führt.
Warum findet Elasticsearch meine EAN nicht?
Wenn die EAN im Index als zusammenhängende Ziffernfolge gespeichert ist, sollte sie eigentlich gefunden werden. Probleme treten in drei Konstellationen auf. Erstens: die EAN enthält Trennzeichen wie Bindestriche oder Leerzeichen, die der Standard Tokenizer als Trenner behandelt und die Nummer zerteilt. Zweitens: die Suchanfrage enthält Whitespace, der vom Tokenizer beim Indexieren nicht berücksichtigt wurde. Drittens: die EAN liegt in einem analysierten Feld, das einen Stemmer oder Stoppwort-Filter durchläuft, der mit Ziffern unvorhergesehen umgeht. Die saubere Lösung ist ein dediziertes Feld mit Keyword Tokenizer für EANs und SKUs, parallel zum Volltext-Feld.
Wie geht Elasticsearch mit deutschen Compound-Nouns um?
Standardmäßig gar nicht. Der Standard Tokenizer behandelt "Edelstahlspülmaschine" als ein einziges Token. Um Teiltreffer zu ermöglichen, brauchen Sie entweder den german_analyzer mit zusätzlichem hyphenation_decompounder Token Filter oder einen NGram Tokenizer, der alle Substring-Kombinationen erzeugt. Die Decompound-Lösung ist sauberer, aber pflegeintensiv: Sie braucht eine Hyphenation Pattern Datei, die regelmäßig gegen neue Produktkategorien getestet wird. Die NGram-Lösung ist robuster, aber bläht den Index auf den Faktor 5 bis 10 auf.
Warum wenden sich Unternehmen von Elasticsearch ab?
In unseren Audits sehen wir drei dominierende Gründe. Erstens: der Lizenzwechsel von Apache 2.0 zu SSPL im Jahr 2021 hat juristische Unsicherheit geschaffen, besonders für Unternehmen mit strengen Open-Source-Richtlinien. OpenSearch und andere Forks sind eine Antwort darauf. Zweitens: die kumulierten Betriebs- und Wartungskosten übersteigen oft das ursprüngliche Budget, sobald Kataloge wachsen und Anforderungen an Relevanz und Tokenizer-Qualität steigen. Drittens: spezialisierte Such-Lösungen liefern KI-Features wie semantisches Verständnis und Vektorsuche out-of-the-box, während Elasticsearch hier nur die technische Grundlage bietet und die Anwendungslogik vom Kunden gebaut werden muss.
Wie lässt sich eine hybride Suche in Elasticsearch realisieren?
Elasticsearch bietet seit Version 8 native k-NN-Suche und Vektorindizes. Eine echte Hybrid-Lösung kombiniert klassische BM25-Token-Suche mit Vektorsuche und gewichtet die Ergebnisse. Die Umsetzung erfordert ein Embedding-Modell, einen Embedding-Pipeline-Job bei jedem Indexierungs-Schritt und eine Reranking-Logik im Query. Wer das selbst aufbaut, sollte mit mindestens 60 bis 100 Personentagen Initial-Aufwand und einem dauerhaften Search-Engineer im Team rechnen. Spezialisierte Lösungen wie Volt Search® liefern diese Pipeline als Infrastruktur, sodass Ihr Team sich auf das Produkt konzentrieren kann statt auf die Such-Architektur.
Welcher Tokenizer eignet sich für Shopware oder Magento?
Beide Plattformen können mit Elasticsearch oder OpenSearch im Backend arbeiten. Der ausgelieferte Default ist in der Regel der Standard Tokenizer mit Lowercase und ASCII Folding. Für deutsche Mid-Enterprise-Shops empfiehlt sich der Wechsel auf einen german_analyzer mit zusätzlichem Decompounder und dediziertem Keyword-Feld für EANs und SKUs. Wenn der Pflegeaufwand zu hoch wird oder die Null-Treffer-Rate trotz Tuning über 5 Prozent bleibt, lohnt der Wechsel auf eine spezialisierte Infrastruktur, die semantisches Verständnis mit klassischer Token-Suche kombiniert. Unsere Praxis-Hinweise für Shopware-Shops finden Sie unter Shopware Suche funktioniert nicht.
Bereit für eine Suche, die EANs versteht und Compounds auflöst?
Tokenizer-Tuning ist eine Disziplin für sich. Wer es richtig macht, gewinnt einige Prozentpunkte Conversion. Wer es jahrelang macht, baut sich einen kontinuierlich wachsenden Wartungs-Backlog. Volt Search® von BatteryIncluded löst das Problem auf der Architekturebene: Hybrid LLM Search kombiniert klassisches Token-Matching, Vektorsuche und Intent-Verarbeitung in einer entkoppelten Infrastruktur. Cookieless, DSGVO-konform, Made in Germany, ohne Tokenizer-Reverse-Engineering.
Zu Ihrer kostenlosen Demo und erleben Sie live an Ihren eigenen Produktdaten, wie Volt Search® EANs, Artikelnummern und deutsche Compounds zuverlässig findet. Ohne Cluster, ohne Tracking, ohne lange Setup-Phase.